
A estas alturas toda organización o empresa que se precie tiene presencia digital, como se suele decir, si no estás en Internet no existes. Para construir una imagen de marca es necesario tener al menos una web propia y con dominio propio (los hosting gratuitos están muy bien para experimentar pero a nivel profesional daría una imagen similar a ir al trabajo en pijama). En estos últimos años han aparecido nuevos dispositivos capaces de acceder a la web (smartphones,tablets,smart tvs,etc), cada uno de ellos con distinta resolución y tamaño de pantalla.

Como es de suponer, según el dispositivo empleado variará la visualización y experiencia de usuario (aunque a priori todos sean capaces de acceder al mismo contenido), por ello es necesario que nuestra web se adapte de la mejor forma posible utilizando el llamado Responsive Web Design (RWD). En este tutorial se va a mostrar como hacer una web responsive y de paso se incluirá una librería jQuery para simular un elemento propio de plataformas móviles.
Responsive Web Design
El RWD o Responsive Web Design es un enfoque de diseño cuyo objetivo es que cambie dinámicamente la forma de visualización de una página según las características del dispositivo que acceda, para conseguirlo se trabaja con la capa de presentación, es decir, sólo es necesario modificar las hojas de estilo CSS, por lo tanto el propio diseñador puede realizar el trabajo sin afectar al resto de capas.
Antes de su aparición, se creaba una versión móvil para mejorar la experiencia de usuario en caso de que el acceso fuera desde un dispositivo diferente a un ordenador, entonces, ¿para qué aplicar el RWD? Las ventajas de este enfoque son varias, principalmente que no se duplica contenido (y por tanto no penaliza el SEO) y que no es necesario modificar la lógica de negocio ni la información almacenada (ya que sólo se actúa sobre la capa de presentación), en consecuencia se ahorra bastante trabajo y se simplifica el diseño, mejorando sensiblemente la mantenibilidad. Como contrapartida es necesario enviar más datos en cada petición, pero si la página está bien diseñada el incremento es perfectamente asumible.
El libro de referencia para entender este diseño es «Responsive Web Design», donde Ethan Marcotte explica su historia, los principios que se deben seguir y cómo aplicarlos. Según este libro se deben cumplir varias condiciones para que una web sea responsive:
– Debe tener una estructura flexible, donde se deben evitar los tamaños fijos (ya sea en píxeles, pulgadas,etc) usando tamaños relativos (porcentajes,em’s) en su lugar. El resultado será que el tamaño de los elementos no será siempre el mismo, sino que se adaptará a la resolución de la pantalla donde se muestra.
– Los Elementos multimedia deben ser flexibles, de forma similar al caso anterior, se pretende que las imágenes, videos y el resto de elementos multimedia sea capaz de adaptar su tamaño en función de la resolución de la pantalla donde se renderiza. Hay que tener en cuenta que algunos navegadores antiguos (principalmente versiones de IE6 y anteriores) no son compatibles con atributos que se utilizan para lograr esta flexibilidad, por lo que se deben tener alternativas si se prevé que un porcentaje considerable de visitantes usen cualquiera de esos navegadores (IE6 viene incluido por defecto con Windows XP, el cual sigue presente en muchos equipos a pesar de que Microsoft ha dejado de darle soporte desde principios de este año)
– Se usan Media Queries (las cuales están disponibles desde la especificación de CSS3) cuya función es seleccionar qué estilos se aplican a la página. Cada Media Query tiene un conjunto de estilos que se aplicarán siempre que su Media Type (el tipo de medio puede ser una impresora, tv, etc) encaje con el dispositivo y si se cumplen las condiciones que se le han asignado (como que tenga un ancho máximo, tenga una determinada orientación, etc). En la práctica el Media Type no es muy útil para los dispositivos actuales, sino que se emplean las condiciones adicionales para adaptarse a los dispositivos, por ejemplo, si queremos que se adapte a un móvil de pantalla FullHD será necesario al menos una Media Query que tenga en cuenta el ratio, mientras que si queremos adaptarnos a un móvil de gama baja deberíamos usar al menos una Media Query que filtre por una resolución baja.
Aún falta un último detalle para que la página se muestre completamente adaptada a la pantalla, y es la inclusión de la metaetiqueta viewport a las páginas donde se pretendan aplicar los estilos. Su función es encargarse de configurar a qué escala se mostrará la página y asignarle la anchura donde deberán encajar todos los elementos de la página. Fue creada por Apple para su navegador Safari a fin de mejorar la visualización de las páginas web al utilizar el iPhone, pero con el tiempo otros navegadores lo han copiado tambien le han dado soporte.
Ejemplos sin RWD
Ahora que ya sabemos más acerca de RWD voy a analizar algunas páginas que no lo aplican, con lo que saldrán a relucir las inconvenientes que ello conlleva si el acceso no se hace desde un ordenador (por no extenderme demasiado he obviado el problema de mostrarlo en PCs empequeñeciendo la ventana del navegador).
La primera que voy a analizar es la página de la URJC (Universidad ¿ex? Rey Juan Carlos), donde estudiamos en su dia casi todos los miembros del blog. Su tráfico aproximado es de 700k de usuarios al mes, hay que decir que no es posible conocer información relativa a los dispositivos desde los que se ha accedido, pero es muy probable que gran parte de ellos dispongan de un smartphone y les resulte mas cómodo que hacerlo desde el ordenador (sobre todo si no se encuentran en casa). Si intentan acceder con un móvil de gama media-alta (pongamos que con pantalla 720p) verían una imagen como la que se muestra mas adelante.
Los emuladores de móviles de Chrome y Firefox muestran la web con ese aspecto, pero según el dispositivo puede mostrarse la web completa, en cualquier caso en un espacio tan pequeño es un engorro ver la información aun usando un móvil de pantalla grande (siendo estudiante, en un país en crisis y con la subida del precio de las matrículas este año lo más normal es que la pantalla que usen sea más bien pequeña).
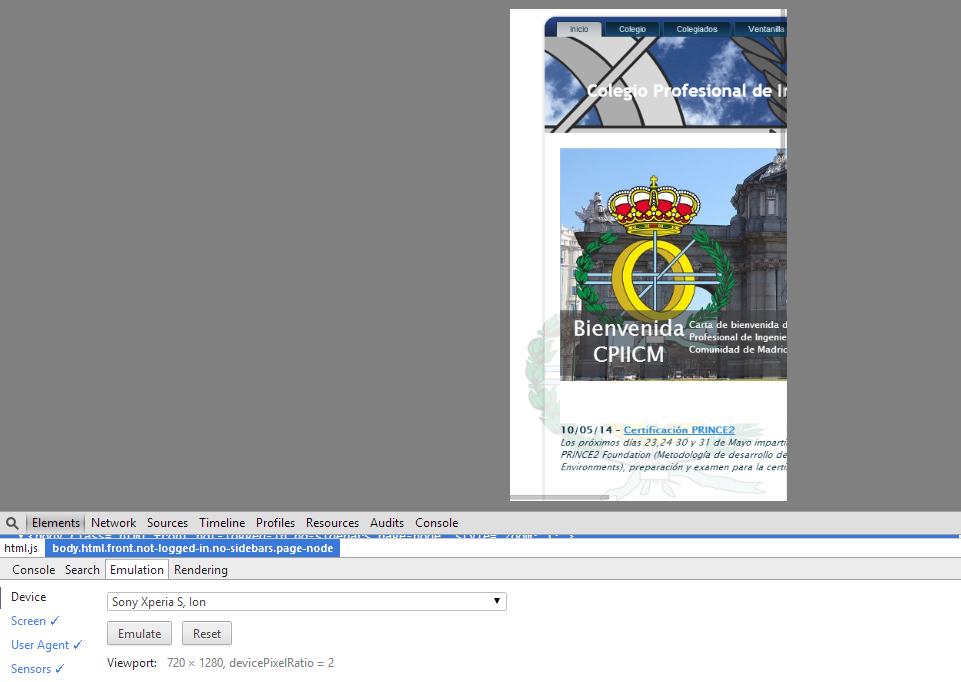
Veamos otro ejemplo, el CPIICM, cuya página está creada con Drupal (según se puede apreciar en el código) y a priori se espera que sea de calidad, pero como en el caso anterior también es farragoso su uso en el móvil. Teniendo en cuenta que los colegiados pagan una cuota anualmente, da la sensación de un mantenimiento pobre (no tenían por qué complicarse mucho ya que existen un montón temas responsive para Drupal)

Ejemplos de páginas con RWD
Ahora voy a enseñar algunas páginas que si se han molestado en aplicar RWD. Dado que el primer ejemplo que he puesto anterior era de una universidad, en este caso voy a destacar la página de la universidad donde no llegó a graduarse el bueno de Mark Zuckerberg. En este caso el diseño es mas funcional y agradable, a diferencia de los ejemplos anteriores se puede ver toda la información sin tener que pelearse con el zoom y se tiene mejor experiencia de usuario, como resultado el visitante considerará su móvil como una alternativa viable al ordenador, con la ventaja de poder acceder desde cualquier lugar (lo que incrementa las posibilidades de que el número de visitas aumente).

Pero en España también tenemos universidades que cumplen, como la UC3M o la UEM (siendo la primera pública y la segunda privada). Luego están casos como la UCM que lo han dejado a medias (no se comporta bien con algunas resoluciones)


Para los que seáis poco empáticos (o directamente unos psicópatas) voy a ejemplificar gráficamente la reacción de los visitantes de vuestra web que pretendan acceder con su móvil low-cost (aka crisis-friendly). Pongamos que el visitante es Florentino Pérez (puede ser que se le haya roto su iPhone y se haya comprado un móvil barato porque tiene que ahorrar para el nuevo Bernabéu).

Sin RWD

con RWD
Si os interesa el tema, en el próximo post se enseñará una web básica que siga el RWD, siguiendo los puntos explicados para que se entienda mejor, además se usará un plugin jQuery que hará que el resultado final tenga un aspecto similar a una aplicación móvil nativa, pero eso ya otro día.





